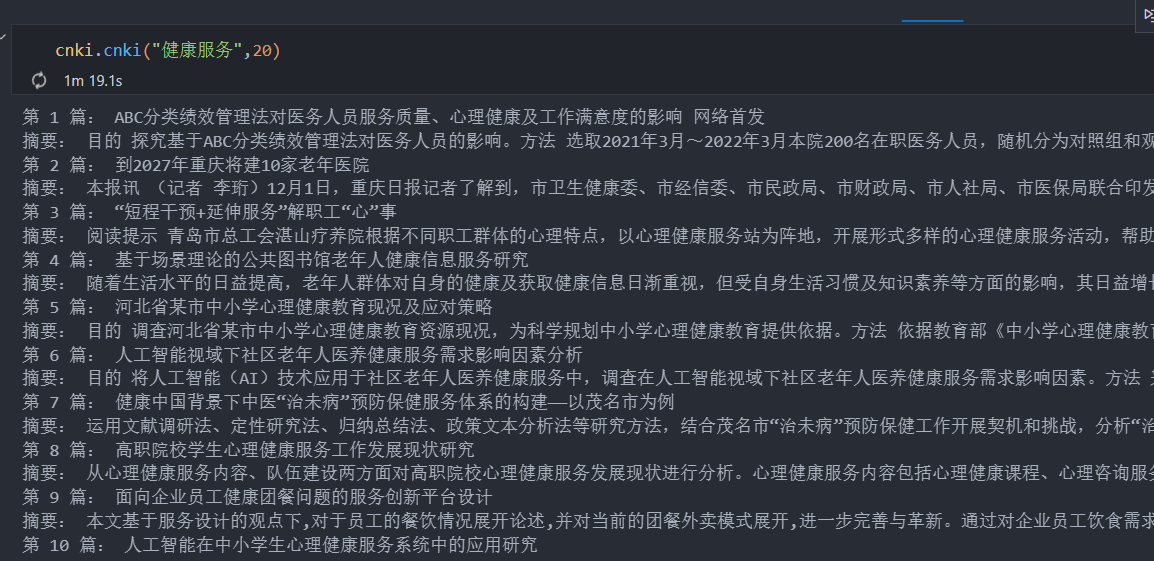
第13期
本期以实用为导向,介绍如何使用selenium模块实现知网条目抓取
个人学习用
2 实现效果
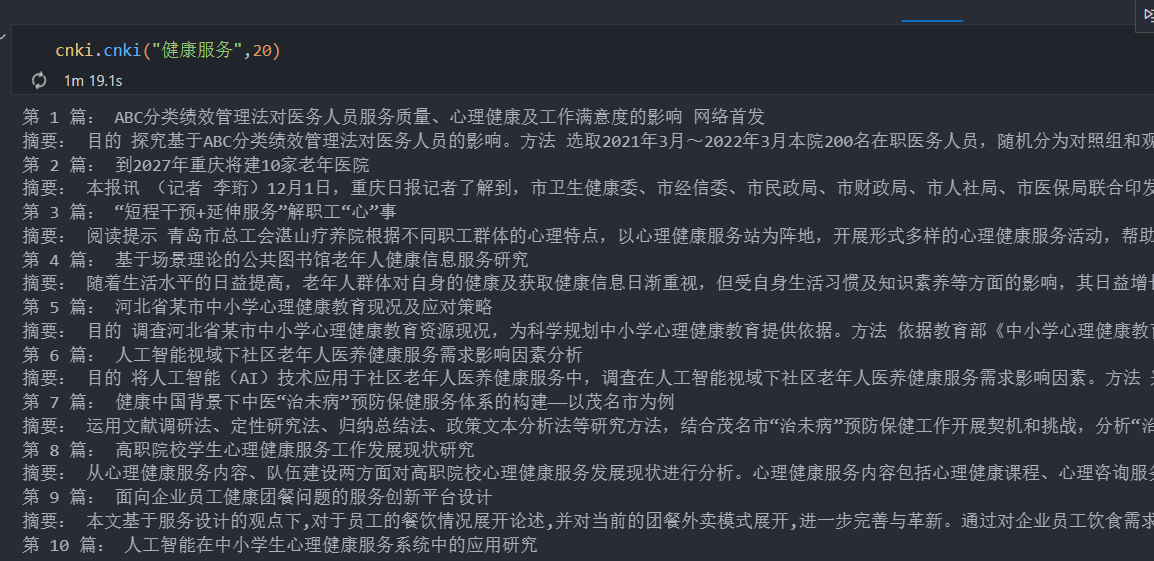
根据主题词和设定论文数即可实现知网论文信息批量获取
3 python总代码
4 代码剖析
预先准备
下载浏览器的webdrive,以便后续代码调用
网址(https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/)
导入模块
- 导入模块
- 选择部分默认设置
- 加载webdrive

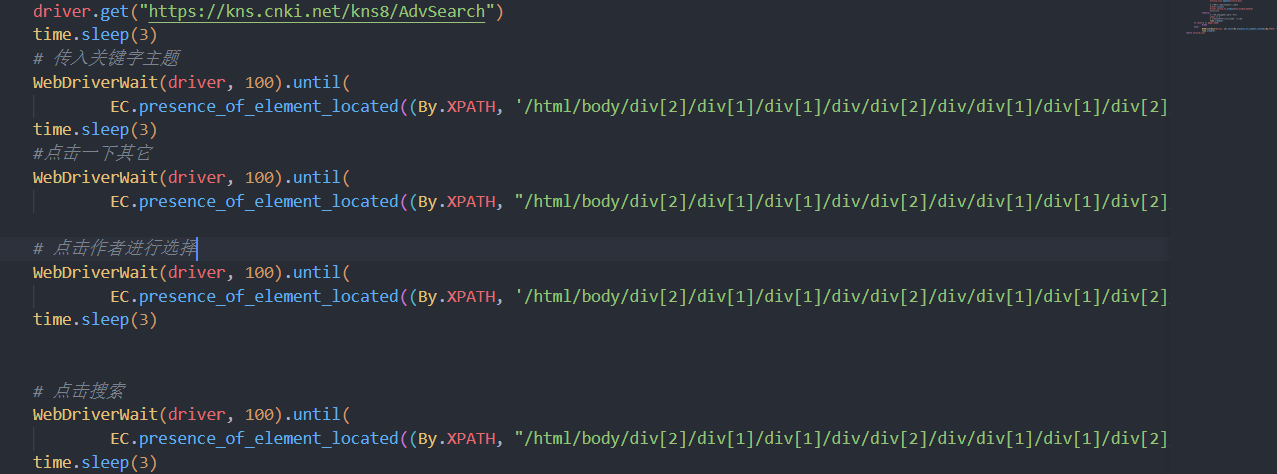
进入搜索界面并输入搜索主题内容
- 模拟打开知网高级搜索界面
- 查找网页元素。在对应input框内插入搜索词(可自定义)
模拟点击进行搜索
模拟鼠标操作,进行循环
- 循环主体代码
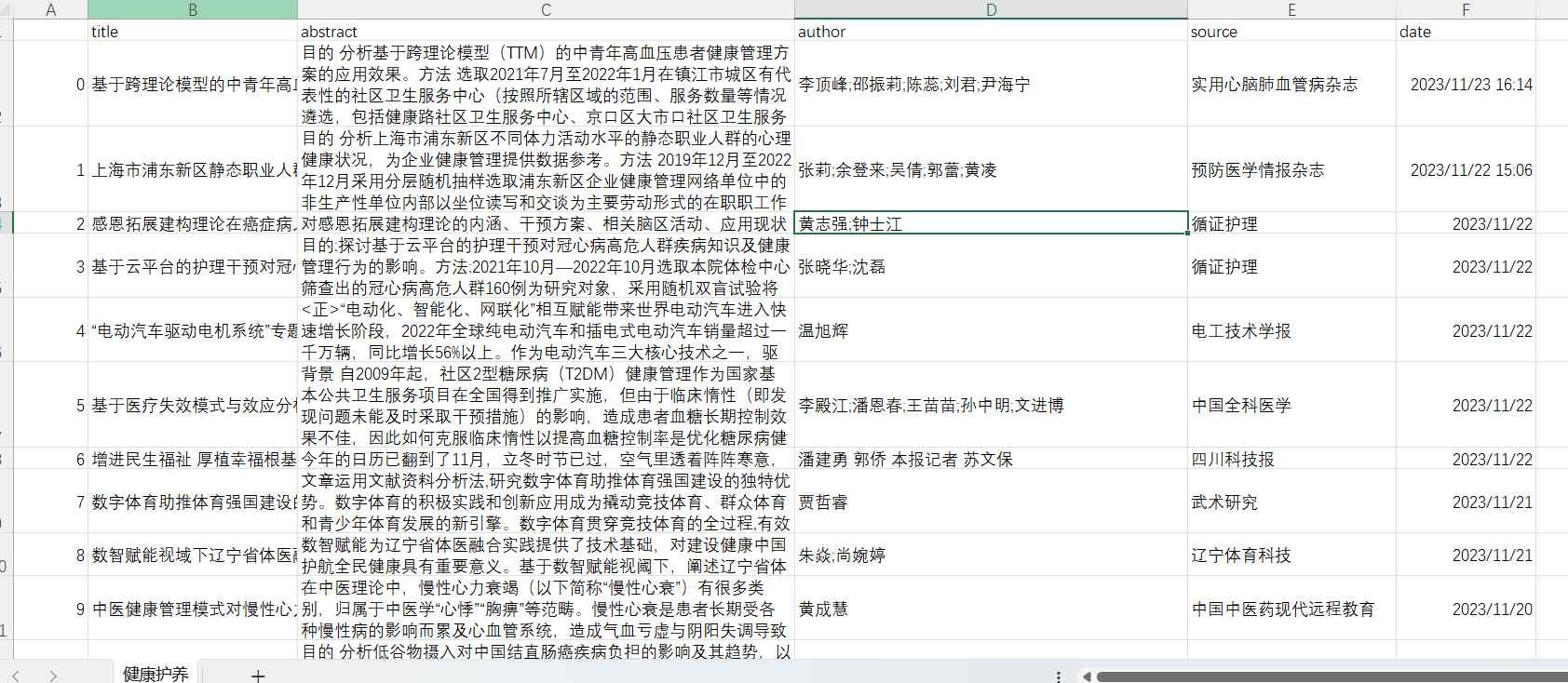
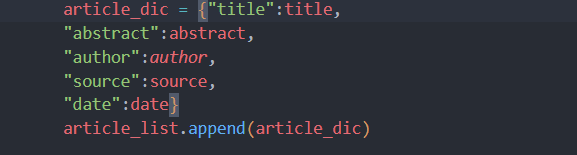
- 获取当前条目的信息,包括作者,期刊,标题及日期
- 模拟点击进入条目主页,获取摘要信息。
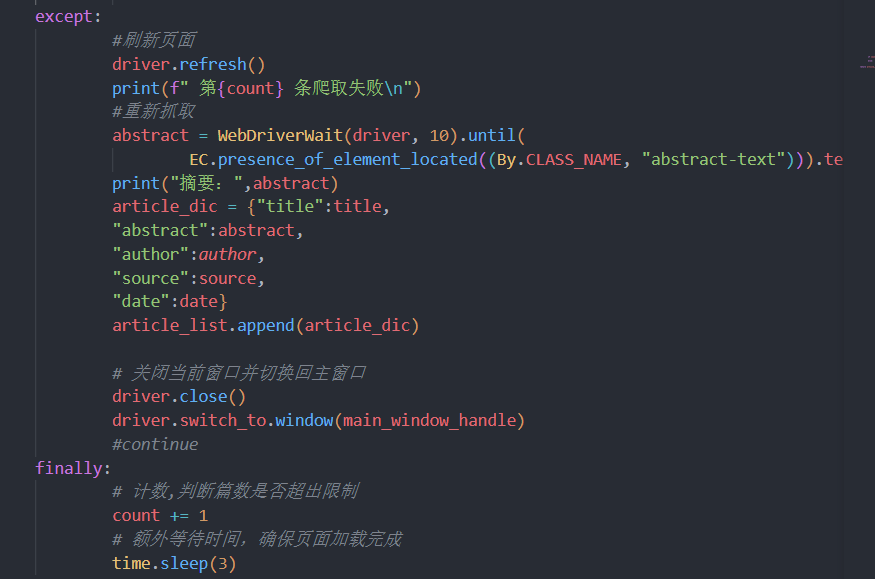
- 保存信息到字典文件,以便后续保存
- 切换回主搜索界面,进行循环
- 由于部分网页加载不完全,可能会无法抓取摘要。添加try-except。失败时刷新网页,保证循环正常进行
- 最终返回article_list列表
保存结果
实用pandas模块,保存至csv文件里







5 注意
- 代码基于selenium,稳定性好,不风控,但速度慢
- 代码中关于信息填入,以及抓取的条目,可以进行很好的自定义。
- 具体如何实现,可参考selenium如何抓取网页元素(XPATH选择已经很好用)
- 仅供文献大量阅读时用。

